Demystifying Data Science
Some people might remember that in 2006, there was no such a thing as Data Science. People were either called data miners, or experts in intelligent systems. The projects being done were mostly on text analytics, data classification, image recognition and robotic without the label 'data science'.
In 2012 the word 'data science' started appearing. Data-miners did a great job at the time in finding correlations and classification of data. Businesses started to understand the value data-mining and machine learning could bring. Therefore, the job-title data science started to become fashionable.
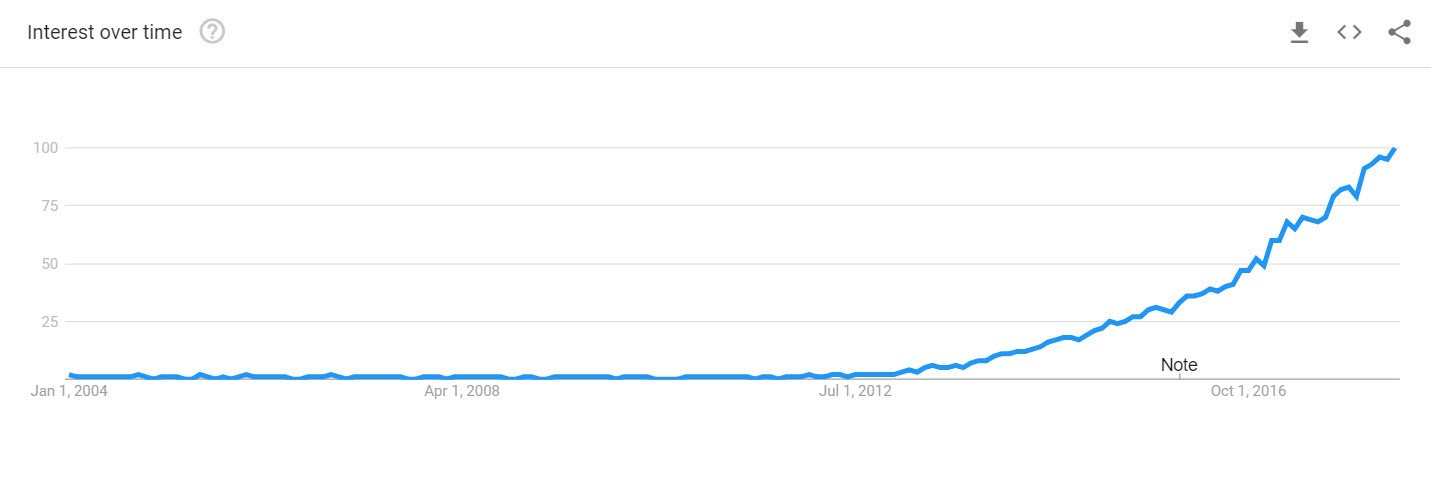
The rise of big data technologies like Hadoop, Spark, and NoSQL databases created new opportunities to process and analyze massive datasets. This technological evolution coincided with the increasing digitization of business processes, generating unprecedented amounts of data.
Today, data science encompasses several key areas:
1. Statistical Analysis: The foundation of data science lies in statistical methods for understanding patterns, relationships, and trends in data.
2. Machine Learning: Algorithms that can learn from data and make predictions or decisions without being explicitly programmed for every scenario.
3. Data Engineering: The infrastructure and tools needed to collect, store, and process large volumes of data efficiently.
4. Data Visualization: The art and science of presenting data insights in a clear, compelling visual format that stakeholders can understand and act upon.
At INSEA IT, we approach data science as a multidisciplinary field that combines domain expertise, programming skills, and statistical knowledge to extract meaningful insights from data. Our goal is to turn raw data into actionable intelligence.
// Remember: Data science is not magic - it's methodical problem-solving with data